
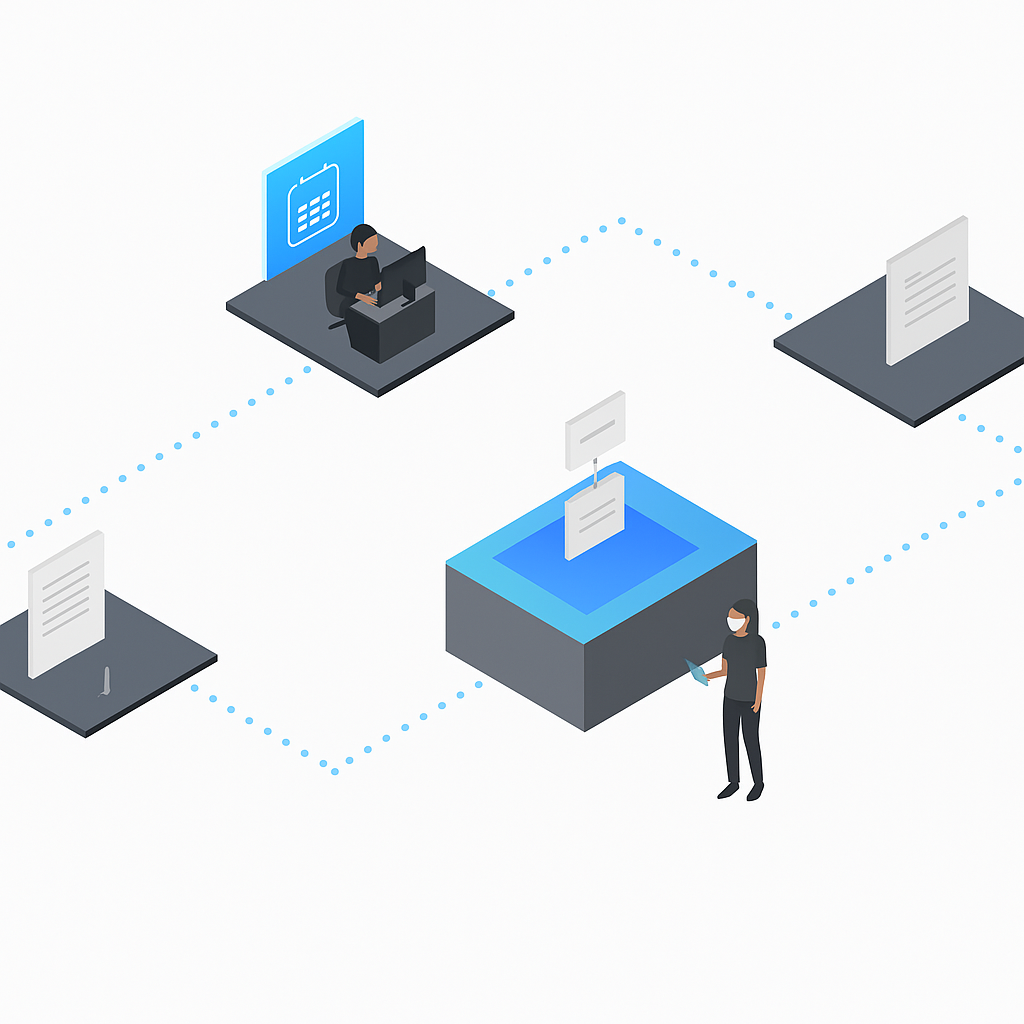




Scan and submit documents from smartphones or tablets for real-time processing.

Extract both printed and handwritten text with high accuracy using Optical Character Recognition.

Capture data from emails, faxes, cloud storage, and digital files.
Categorizes documents with AI for faster processing and routing.

Automates workflows with IBM Robotic Process Automation, leveraging Datacap MetaBot.

Ensures data accuracy before exporting it to business systems for downstream processes.
Integrates within IBM Cloud Pak® for Business Automation, enhancing enterprise-wide automation.

Helps businesses reduce operational overhead associated with paper-based workflows.

Extracts data in over 50 languages, making it adaptable for global enterprises.

Accelerating Intelligent Document Processing with IBM Datacap
A large financial services organization needed to modernize how it ingested, validated, and processed massive volumes of documents—including loan applications, KYC forms, invoices, and customer correspondences. Manual document handling created delays, errors, and compliance risks.
By implementing IBM Datacap with Nexright, the organization built an automated, intelligent document capture and classification system. The solution transformed how documents were scanned, digitized, extracted, and routed—resulting in faster processing, improved accuracy, and enhanced regulatory compliance across business units.
Business challenge
The organization relied on heavily manual processes to capture and process documents submitted through branches, customer portals, email inboxes, and third-party systems. These processes were labor-intensive, error-prone, and unable to scale with increasing customer volumes.
Key challenges:
- High manual effort in reviewing and entering data from documents.
- Slow turnaround times for loan approvals, customer onboarding, and service requests.
- Inconsistent accuracy, leading to rework and operational inefficiencies.
- Compliance risks arising from missing, mishandled, or inaccurate documentation.
- Lack of standardization across multiple business units and geographic locations.
- Limited integration with downstream systems such as core banking, CRM, ERP, and workflow engines.
The organization required a centralized, intelligent, and scalable document automation solution capable of reducing processing time, improving extraction accuracy, and ensuring compliance across the document lifecycle.
Solution
Partnering with Nexright, the organization deployed IBM Datacap as the foundation of its intelligent document processing platform. Datacap automated document capture, classification, extraction, validation, and routing across departments.
Solution Highlights:
- AI-Enabled Document Classification
Datacap’s machine learning–based recognition automatically categorized diverse document types (KYC forms, IDs, invoices, statements) with high accuracy. - Automated Data Extraction
Extracted key fields using OCR, NLP, and configurable rules—reducing manual data entry and improving consistency. - Straight-Through Processing (STP)
Integrated validation rules and business logic enabled documents to flow directly into back-office systems without human intervention. - Fraud and Compliance Controls
Enforced mandatory document checks, completeness validation, and audit trails aligned to regulatory frameworks. - Workflow Integration
Seamlessly connected with ERP, CRM, IBM Cloud Pak for Business Automation, and third-party systems for end-to-end automation. - Omnichannel Capture
Enabled ingestion from scanners, mobile uploads, email, portals, and legacy systems—centralizing all document pipelines.
Solution components
- IBM Datacap
- IBM Cloud Pak for Business Automation
- IBM Business Automation Workflow (optional integration)
Intelligent Document Classification
AI-driven recognition automatically identifies document types, even when layouts vary. This improves accuracy, reduces manual review, and accelerates processing.
Automated Data Extraction & Validation
Extracts structured and unstructured data using OCR, NLP, and rule-based validation—ensuring high-quality data before entering downstream systems.
Scalable Processing Engine
Handles millions of documents annually with elastic scaling across on-premises and hybrid cloud environments.
Result
- Reduced document processing time by 70%, enabling faster customer onboarding and loan approvals.
- Improved data accuracy by 90% through automated extraction and rule-based validation.
- Cut operational costs by 45% by reducing reliance on manual data entry teams.
- Enabled real-time compliance with digital document trail and auto-validation of mandatory fields.
- Accelerated automation adoption by integrating with IBM Cloud Pak for Business Automation and downstream core systems.
- Increased employee productivity by eliminating repetitive document-handling tasks.
Nexright and IBM Datacap transformed how we process documents across our enterprise. Automated capture and extraction dramatically reduced turnaround times and compliance risks. What once required hours of manual effort now happens in minutes—with far higher accuracy.
— Head of Operations, Leading Financial Services Organization

Accelerating Document Digitization and Workflow Efficiency with IBM Datacap
A large fleet management and vehicle rental services provider relied heavily on paper-based documentation to manage bookings, contracts, inspections, service records, and billing workflows. Manual data entry slowed operations, introduced errors, and made it difficult to scale as customer demand grew.
By implementing IBM Datacap with Nexright, the organization automated the capture, classification, and extraction of data from multiple document types — enabling faster onboarding, accurate data processing, and seamless integration into downstream business systems. The result is a smarter, more efficient content management experience that reduces manual workload and accelerates decision-making.
Business challenge
The company’s rapid expansion created an urgent need for streamlined document processing. Thousands of forms — ranging from rental contracts to maintenance reports — were being scanned or manually keyed into internal systems. This created operational bottlenecks and impacted service quality.
Key Challenges:
- High manual effort required to capture and validate data across multiple document types.
- Slow turnaround times for contract creation, vehicle check-in/out forms, and billing records.
- Inconsistent document accuracy, leading to compliance risks and customer disputes.
- Limited visibility into document status and workflow progress.
- Difficulty scaling as the organization expanded its fleet and customer base.
The organization needed an intelligent, scalable, and automated document processing solution capable of managing diverse content types while eliminating human error and processing delays.
Solution
Partnering with Nexright, the organization deployed IBM Datacap to automate document ingestion, classification, and data extraction across its core fleet management workflows. Nexright designed an end-to-end intelligent document ecosystem integrated with the organization’s ECM, ERP, and customer service platforms.
Solution Highlights:
- Smart Document Capture:
Automated capture of contracts, checklists, invoices, ID documents, and service records from scanners, email, web portals, and mobile devices. - AI-Driven Classification:
Machine learning models trained to identify document types, apply business rules, and route files to the correct workflow. - Advanced Data Extraction:
High-accuracy OCR and rule-based extraction of customer details, vehicle IDs, contract values, mileage readings, and inspection notes. - Automated Validation & Exception Handling:
Business rules verify extracted data, flag inconsistencies, and route exceptions to staff for quick resolution. - Seamless System Integration:
Nexright integrated Datacap with IBM FileNet, ERP systems, and the customer service platform to support real-time document updates and faster transaction processing. - Operational Analytics:
Dashboards providing visibility into processing speed, error rates, and workflow performance.
Solution components
- IBM Datacap
- IBM FileNet Content Manager
- IBM Cloud Pak® for Business Automation
Multi-Channel Document Capture
Capture documents from scanners, mobile apps, email, and web portals with automated metadata extraction and content validation.
Intelligent Classification
Machine learning models categorize documents — from rental agreements to maintenance logs — and apply workflow rules instantly.
High-Accuracy Data Extraction
OCR and NLP extract structured and unstructured data, reducing human input and minimizing billing or contract errors.
Result
- Cut document processing time by 70%, accelerating onboarding and customer service.
- Reduced manual data entry by 80%, freeing staff to focus on higher-value tasks.
- Improved accuracy by 90% through automated extraction and validation rules.
- Enabled same-day processing of rental contracts and service records across all branches.
- Strengthened compliance, with complete audit trails and centralized document governance.
- Scalable automation foundation that supports company growth without additional administrative overhead.
Before Datacap, we captured lots of data — but we weren’t truly putting it to work. With Nexright and IBM Datacap, we’ve automated document handling end-to-end, reduced errors, and dramatically improved operational efficiency.
— Fleet Operations Manager, Fleet Hire Services

“IBM Datacap has transformed how we process and manage documents, significantly reducing manual efforts and improving workflow efficiency.”
Efraín Pereiro, System Developer, Banco Galicia





