
Return on investment realized within three years.

Reduction in time spent on data analysis tasks.

Month-over-month increase in revenue using NLU-powered insights.
01

Lightning-fast data access, 8 times speedier, while slashing costs across cloud and on-premises data sources.
02

Free up data engineers for high-value tasks with 25-65% fewer ETL requests.
03

Say goodbye to $27 million in manual cataloging costs, just as IBM Global Chief Data Office did.

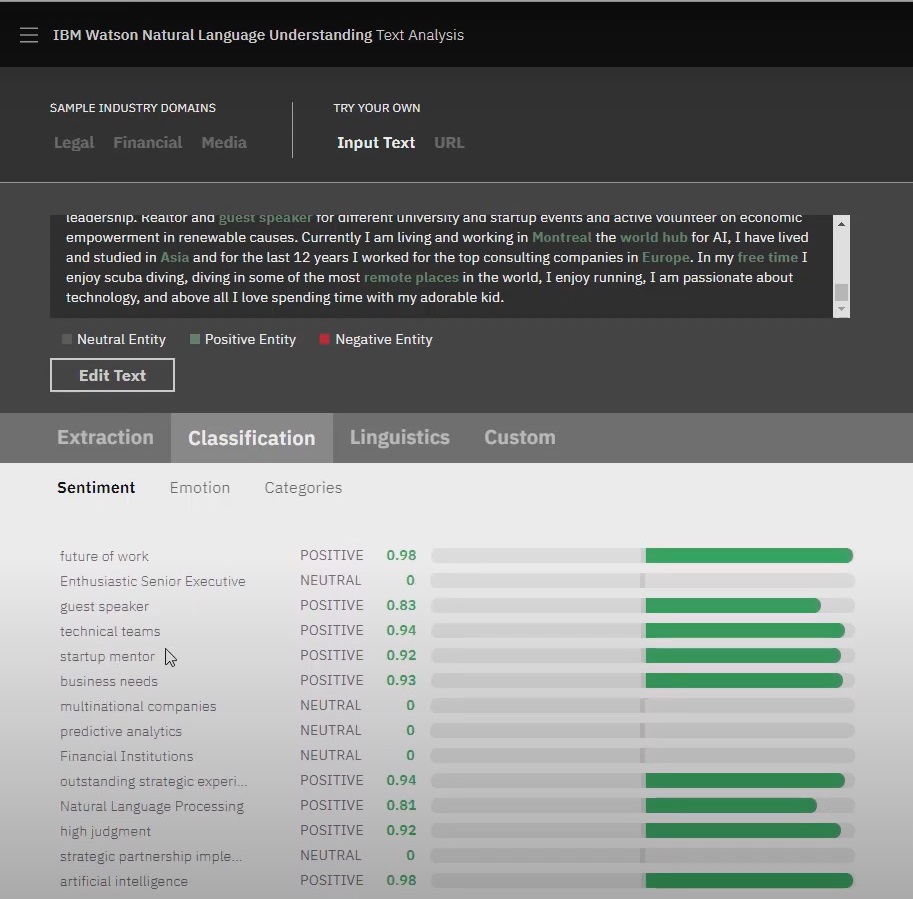
Identify and categorize key entities such as people, places, and events.

Classify data using a detailed five-level hierarchy for improved data organization.

Automate text labeling for enhanced workflow efficiency.




IBM Watson NLU processes over 13 languages, enabling cross-border data analysis.

Seamlessly integrates into existing workflows without needing extensive IT resources.

Available on multiple platforms for increased flexibility and accessibility.
Enhancing Content Intelligence and Optimization with IBM Watson Natural Language Understanding
A digital publishing and marketing organization aimed to eliminate manual analysis bottlenecks in its content optimization workflow. Their analysts spent hours reviewing top-performing pages, extracting insights, and briefing content teams — a process that could not scale with growing demand.
By implementing IBM Watson Natural Language Understanding through Nexright, the organization automated deep content analysis, identified semantic patterns, and generated actionable recommendations. This allowed content strategists to produce higher-quality content in significantly less time, while improving performance consistency across campaigns.
Business challenge
The organization was struggling to maintain a competitive edge in a crowded content landscape. With multiple campaigns, writers, and content formats, the marketing team needed an accurate and scalable way to:
Key Challenges:
- Time-consuming manual content analysis slowing down production cycles.
- Inconsistent insight quality due to subjective human interpretation.
- Difficulty identifying semantic gaps between top-performing and underperforming pages.
- Limited visibility into competitor content structures and audience intent signals.
- Growing content volume outpacing the team’s ability to analyze and optimize effectively.
Leadership wanted a data-driven recommendation engine that could automatically extract insights, accelerate workflows, and enable content teams to publish high-impact content faster.
Solution
Partnering with Nexright, the organization deployed IBM Watson Natural Language Understanding as the core intelligence engine within its content operations workflow. Watson NLU’s advanced linguistic models were used to automate semantic analysis, reveal intent patterns, and surface insights that previously required hours of human effort.
Solution Highlights:
- Automated Semantic Analysis:
Watson NLU extracted entities, keywords, sentiment, categories, and semantic relationships from top-ranking pages — replacing hours of manual analysis. - Competitive Intelligence Mapping:
The platform compared competitor content structures, tone, and topical gaps, summarizing strengths and missed opportunities. - Content Quality Scoring:
Using Watson NLU outputs, Nexright implemented a scoring model that rated content drafts across readability, coverage, and keyword alignment. - Insight-to-Recommendation Engine:
Nexright built a rules-based engine converting NLU insights into actionable writing recommendations for content teams. - Scalable Workflow Integration:
Insights were delivered through an internal dashboard, helping strategists produce consistent, high-performing content across brands and formats.
Solution components
- IBM Watson Natural Language Understanding
- IBM Cloud Pak® for Data (optional integration for enterprise deployment)
Automated Content Intelligence
Watson NLU analyzes large volumes of content in minutes, extracting sentiment, emotion, entities, keywords, and categories — eliminating manual review and accelerating content planning.
Competitor & Market Insight Extraction
Identifies semantic trends, content positioning strategies, and topic gaps across competitor pages, providing a data-driven foundation for outperforming them.
Intent & Audience Profiling
Identifies searcher intent signals and emotional tone patterns that resonate with audiences, enabling content teams to tailor messaging precisely.
Result
- 70% reduction in content analysis time, accelerating editorial pipelines across teams.
- 40% improvement in content ranking consistency, driven by data-driven optimization.
- Higher CTR and engagement due to better intent alignment and semantic coverage.
- Improved content quality with standardized guidelines and automated scoring.
- Analyst workload reduced by 60%, allowing teams to focus on strategic initiatives.
The organization now publishes content faster, more confidently, and with greater consistency — supported by automated insights that scale with business needs.
With Nexright and IBM Watson Natural Language Understanding, we replaced hours of manual evaluation with instant, data-driven insights. Our content teams now produce more accurate, higher-quality work in a fraction of the time.
— Director of Content Strategy, Digital Media Organization
Accelerating Inquiry Classification and Operational Efficiency with IBM Watson Natural Language Understanding
A specialized software provider in Japan wanted to reduce the manual workload involved in categorizing thousands of customer inquiries across multiple channels. Their existing process relied on human review, which slowed down response times, increased operational costs, and made it difficult to identify emerging trends.
Partnering with Nexright, the organization implemented IBM Watson Natural Language Understanding (NLU) to automate inquiry classification, extract key conversation insights, and strengthen decision-making across their support teams. The AI-powered model significantly improved prediction accuracy, reduced manual effort, and provided new visibility into customer sentiment and inquiry themes.
Business challenge
The company handled a high volume of inquiries daily—ranging from product questions to service support—for small and midsized business clients. However, the categorization process was entirely manual, leading to:
Key Challenges:
- Large fluctuations in inquiry volume, making it difficult to maintain consistent service levels.
- Manual classification bottlenecks, resulting in slower customer response times.
- Limited visibility into inquiry trends, impacting product planning and customer experience improvement.
- Increasing labor costs, with employee time heavily consumed by repetitive classification tasks.
The organization needed a scalable, accurate, and automated way to classify inquiries and support continuous operational improvement.
Solution
Nexright helped the client evaluate multiple AI options and determine the best-fit approach using IBM Watson Natural Language Understanding.
The solution used Watson NLU to analyze sentences, detect relevant features, extract keywords, and accurately classify messages into the correct categories—reducing the need for human review.
A proof of concept (PoC) demonstrated strong accuracy and suitability for real-world usage. Using Watson NLU combined with training on the client’s historical inquiry data, the team built a customized language model capable of understanding domain-specific terminology, slang, and context.
Once implemented, the automated classification workflow delivered:
- Significant reduction in manual review workload
- Faster identification of topic trends
- Improved customer service efficiency
- A strong foundation for future AI expansion (e.g., generative AI assistants)
Solution components
- IBM Watson Natural Language Understanding
- IBM watsonx.ai (for training, fine-tuning, and model management)
Automated Inquiry Classification
Watson NLU categorizes incoming messages using advanced linguistic analysis, correctly identifying query intent even in short or ambiguous messages.
Custom Domain Language Model
Nexright and the client co-created a model trained on the organization’s own historical data, ensuring high accuracy for industry-specific terms.
Keyword Extraction & Trend Analysis
Key terms and patterns are automatically surfaced to help the team identify emerging issues, customer needs, and product opportunities.
Result
- >51% improvement in prediction accuracy after training the Watson NLU model with custom data
- Significant reduction in manual classification time, enabling support teams to focus on higher-value tasks
- Faster customer response times, leading to improved satisfaction
- New insights into inquiry patterns, driving proactive service improvements
- Lower operational costs, as repetitive work shifted away from human agents
The solution created a measurable improvement in business efficiency while enabling a sustainable, AI-powered support model.
With Watson, we can automatically categorize inquiries with far greater accuracy and speed. The AI-powered workflow allows us to focus on customer needs instead of manual processing. Nexright helped us quickly identify the most effective model and deploy it into production seamlessly.
— Lead IT Manager, Japanese Software Provider

IBM Watson NLU is trusted by a wide range of industries, from marketing and legal to finance and technology. Its success across various sectors underscores its versatility and ability to generate real, measurable business results.





